Baskerville is a real-time, L7 bot and DDoS defense platform built as a streaming ML system. Here’s how it works.
Unsupervised anomaly detection
Conventional machine learning approaches for network attack detection are based around recognizing patterns of behavior, building and training a classification model. This requires large labelled data sets. However, the rapid pace and unpredictability of cyber-attacks make this labeling impossible in real time as well as incredibly time consuming post-incident. In addition, a signature-based approach is naturally biased towards previous incidents and can be outmaneuvered by new, previously unseen, patterns.
- No labeling required: We rely on unsupervised anomaly detection (e.g., Isolation Forest and sequence models), so we don’t need large, hand-labeled datasets—labeling is time-consuming, costly, and impractical in real time.
- Catches the unknown: Instead of memorizing past signatures, models learn each site’s normal behavior and flag deviations, including novel AI-driven bots and slow/low attacks.
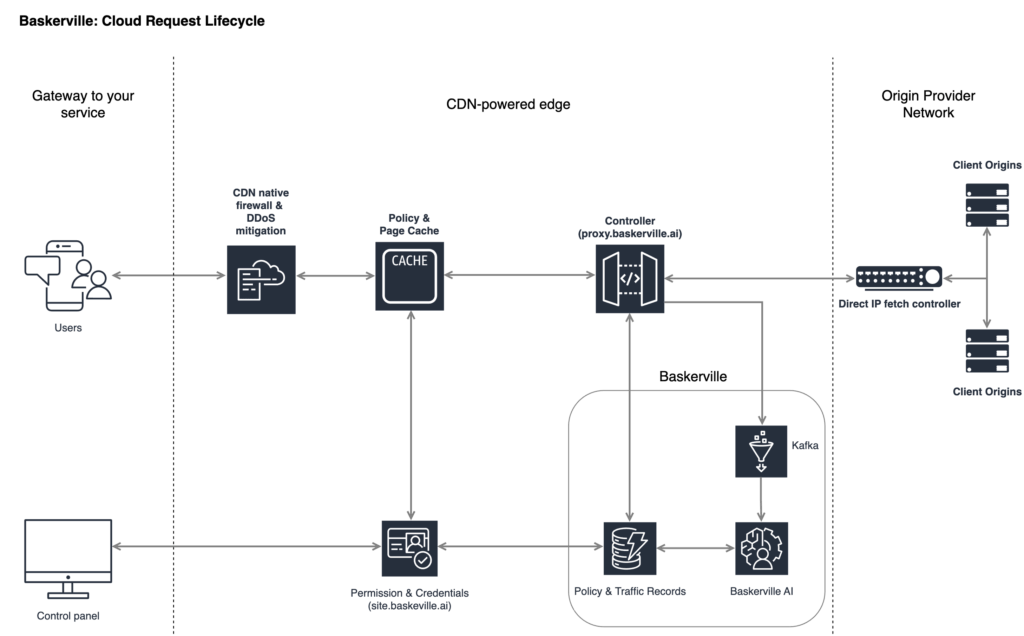
Data pipeline (real-time, Kafka-first)
- Inputs: Layer-7 weblogs from CDN edges (Cloudflare, Amazon CloudFront) and origin proxies.
- Backbone: Apache Kafka with host-keyed partitions to keep all events for the same site ordered together.
- Sessionization: Real-time creation of user sessions (via KSQL/Kafka Streams), grouping requests by session cookie (with IP/host fallbacks).
Feature extraction
- Statistical features: Request rates, status-code histograms, bytes, burstiness, sliding-window aggregates.
- Text/sequence features: Encoded URL paths and navigation sequences (time-ordered URLs).
- Browser environment metrics: TLS/cipher hints, language/timezone, headless signals, and lightweight fingerprint sketches (canvas/WebGL quirks, WebRTC traits) to reveal swarms of “different” browsers sharing the same environment.
Human vs automated separation
- A lightweight gatekeeper classifies traffic as human vs automated (incl. verified search bots), reducing noise and enabling tighter anomaly thresholds on the automated side.
Website-specific anomaly models (trained online)
- Per-site models: Each domain gets its own unsupervised model, continuously trained on the fly from live sessions.
- Algorithms: Isolation Forest for statistical features plus behavior models that learn URL-sequence norms—effective against slow, content-aware bots that mimic humans.
- Drift-tolerant: Models adapt to changing traffic without relabeling or offline retraining cycles.
Action loop: challenge → verify → block
- Suspicious sessions receive progressive challenges (low-friction JS checks up to CAPTCHAs) through CDN integrations.
- Outcomes (pass/fail/hesitation) feed back into the pipeline; confirmed malicious actors are blocked or rate-limited, while legit users proceed.
Observability & storage
- Durable store: All session summaries, decisions, and scores are saved in Postgres for audit and analytics.
- Metrics: We publish challenge rate, bot rate, AI-bot rate, fingerprinting scores, and model health to Prometheus, with Grafana dashboards for real-time visibility.
- Search at scale: Historical weblogs/attacks can be indexed in Elasticsearch for fast investigations and offline experiments.
Platform & integrations
- Kubernetes-native services for elastic scaling.
- Generic APIs to plug into CDNs (Cloudflare, CloudFront) and site backends, decoupling model logic from edge enforcement.
What’s next
- Cluster-level detection: Cross-session/cross-IP clustering to catch AI botnets whose individual sessions look human but align into inhuman patterns at scale.
- Deception/honeypots: Rotating low-SEO bait pages to attract content-hungry AI crawlers and safely exhaust their compute.
- Synthetic adversaries: Continuous red-teaming with AI-driven bot agents.
- Reinforcement loop: Operator feedback (FP/FN tags) closes the loop for ongoing model improvement.